How to search contents of RTF files using Smart Search
As I mentioned in my
Kentico 8 preview article about Smart Search quite a while ago, Kentico 8 comes with full support for indexing the content of attachment files. The list of support files is quite extensive, however there are still some common files missing. In this article I’ll add support for RTF files which is not among files supported out of the box.
To be able to add support for indexing the content of RTF files, first we need to know how attachment content indexing works behind the scenes. The indexing is provided by so called “search text extractors”. The default ones are all in the CMS.Search.TextExtractors namespace.
If you configure your Smart Search index to also index attachment content and rebuild the index, then the indexer goes through each attachment it finds attached to the document it’s indexing and the following occurs:
-
The indexer looks at the extension of the file—if the extension is not among those supported it does nothing. If the extension is among the supported files, it gets the binary data of the file and passes it on to the corresponding text extractor registered in the system for this file type.
-
The text extractor takes the file binary data, interprets it, and returns a pure text representation of the file back to the indexer.
-
The indexer caches the extracted text to the AttachmentSearchContent column of attachment in the DB so next time the content is needed it does not have to be extracted (as this can be quite a resource-demanding process).
-
If the attachment is updated, Kentico makes sure the cached value in AttachmentSearchContent is cleared so the search process can call the extractor again to get fresh data.
Now understanding how indexing files for content works, we can change our goal from “Adding support for RTF files to Smart Search” to the more technical and more specific “Creating RTF text search extractors”.
In this article you’ll learn two things:
-
How to create a custom text extractor to Smart Search
-
How to create a custom module recognized by Kentico just by copying its dll to bin folder.
Let’s start with the extractor class itself. The development process is very easy; you just create your custom class (let’s name it RtfTextExtractor) and implement the interface IsearchTextExtractor. This forces you to implement the method ExtractContent, which turns the binary data of the given physical file to its text representation.
Just one note about why this method does not return string but an XmlData object: it’s because you may want to index parts of your physical file to different fields of your smart search index document. For example, we may want to extract the metadata of the RTF file, such as author, and store it to the field “Author”, while the rest (the actual contents of the RTF file) might go to the default content field.
In this example we will ignore the metadata of the RTF file and just index its contents. To implement the extraction, we’ll use the RichTextBox control as recommended on MSDN, so our extractor will look like this:
The next thing we need to ensure is to let Kentico know about the extractor so it can use it for extracting content from the RTF files. My goal is to create a reusable library that I can quickly copy to any of my Kentico instances bin folder whenever I need this instance to be able to index RTF files. To do that, I will create a Kentico module library. This is done by creating a standard c# class library project, referencing required dlls from the Kentico 8 instance, and then adding a special Module class and one assembly attribute to the AssemblyInfo.cs class.
The module class can have an arbitrary name. The important thing is that you inherit from a CMS.DataEngine.Module class and provide a parameter-less constructor by inheriting from the default constructor and specifying the module name. The inheritance from Module class provides you with a OnPreInit method where you can register your new extractor. This method is guaranteed to be called at application start, so that’s what we need.
The AssemblyDiscoverable attribute in AssembylInfo.cs class then ensures Kentico will load this assembly on application init, look for all the modules in this assembly, and call their OnPreInit methods on application start. It all should look like this:
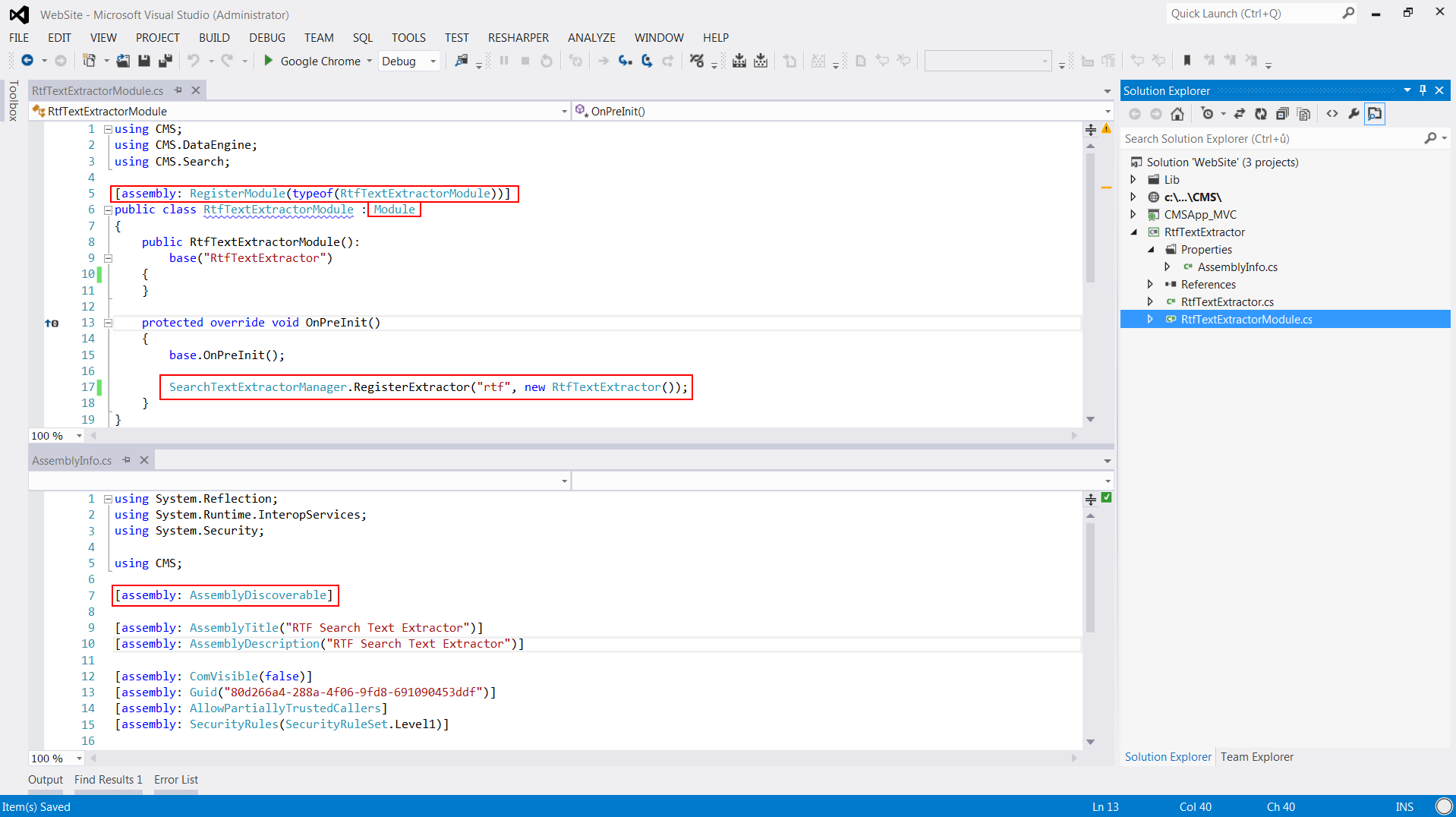
Now we are ready with development. It’s enough to rebuild the project to get the dll and copy it to bin folder of your Kentico instance. Or if you develop in the solution of your Kentico instance, just add a reference to the RTF extractor project to your web project.
This will cause an application restart and if you look in Event log application at an Application_Start event, you should see our module among the modules initialized. Henceforth, your Kentico instance supports the indexing of RTF files! Wasn't that easy? :-)
You can download the complete code of this library along with compiled dlls from our
Marketplace.
PS: Just a quick tip at the end. If you would like to have search functionality over the contents of your media library files, there is nothing easier than creating a custom search index. This will call the extractors API to get the contents of the media files, as this API is public. So to get the text contents of a Word file you’d just call this line of Kentico API:
var xmlData = new CMS.Search.TextExtractors.DocxSearchTextExtractor(...);
Did you know there was such an API in Kentico 8? :-)