|
|

Outgoing tasks (direction from Kentico CMS) |

|

|

|

|
|
Outgoing tasks (direction from Kentico CMS) |
|
|

|
|
|
|
Outgoing tasks (direction from Kentico CMS) |
|
|
|
|
|
Outgoing tasks (direction from Kentico CMS) |
|
|
|
|
|
|
||
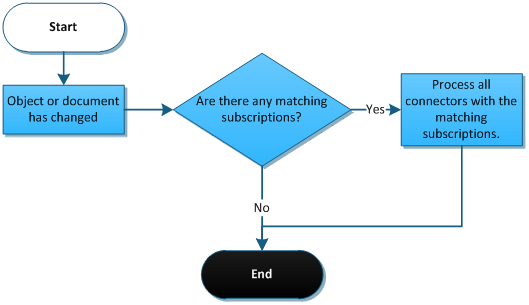
The outbound direction of integration is dependent on so called subscriptions. These allow you to specify which objects or documents you want to synchronize. When a user or the system itself performs an operation (such as create, update or delete) that corresponds with a subscription, the system passes the request to a connector either synchronously or asynchronously (this also depends on settings of the subscription).
Subscriptions are used to define a scope over objects and documents. They can be basically understood as conditions – and when the conditions are met, the object or document is passed to further processing.
The following diagram illustrates how subscriptions fit into the whole integration process:
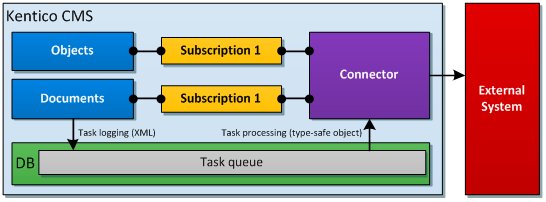
More details can be found in Connectors -> Implementation of outbound direction.
Unlike the inbound direction, the outbound direction supports two types of processing — asynchronous and synchronous.
When you choose to process tasks asynchronously, object or document data are firstly stored in the database (we say that a task was logged in the tasks queue). Even if the external system is not currently accessible for some reason, the tasks are logged to a queue, which preserves the order of performed actions and prevents the synchronization from being lost. The tasks can be reliably processed once the external system is operative again. Another major advantage of this approach is that you don’t lose the data of the tasks even if processing fails.

To ensure maximum performance, the logging and processing is postponed till the application reaches its EndRequest event, as can be seen in the following figure:
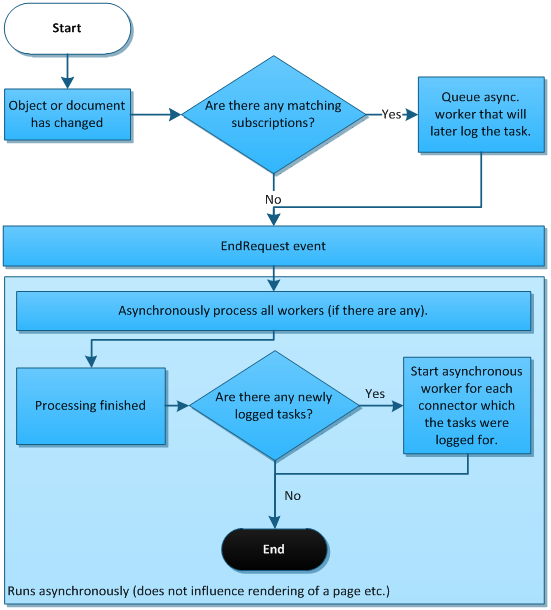
Asynchronous processing is highly scalable as all time‑consuming operations are performed asynchronously. This approach doesn’t have any major disadvantages and can be used for most scenarios.
As mentioned above, the processing starts basically on EndRequest. Alternatively, it can be launched by clicking Synchronize (![]() ) in Site Manager -> Administration -> Integration bus -> Outgoing tasks. This can come in handy when the processing was previously turned off in settings or when the processing failed for some reason that has passed. Please note that processing doesn’t start on EndRequest when the object or document has been changed in an asynchronous thread (e.g. in New site wizard when the Log integration tasks option is enabled). This limitation will be hopefully removed in one of the future versions of Kentico CMS.
) in Site Manager -> Administration -> Integration bus -> Outgoing tasks. This can come in handy when the processing was previously turned off in settings or when the processing failed for some reason that has passed. Please note that processing doesn’t start on EndRequest when the object or document has been changed in an asynchronous thread (e.g. in New site wizard when the Log integration tasks option is enabled). This limitation will be hopefully removed in one of the future versions of Kentico CMS.
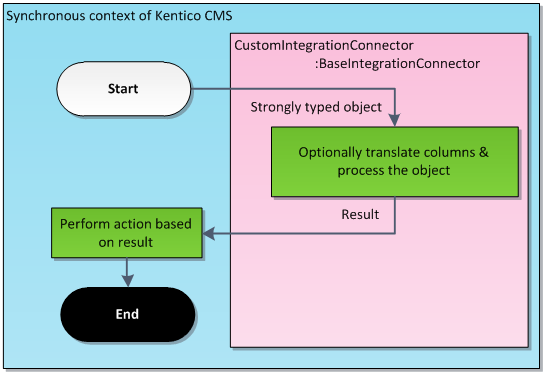
When the processing thread starts, the connector starts to fetch tasks from the oldest to the newest (it is the classic queue principle). A fetched task is transformed to a strongly typed object and passed to the methods implemented by the developer in the connector class. Some additional methods might be called, e.g. when a foreign key translation is desirable. When the task is processed, no matter whether successfully or not, the result value (of type IntegrationProcessResultEnum) is returned to notify the connector. Depending on the result, the connector decides what to do next.
The following scheme illustrates the whole procedure:
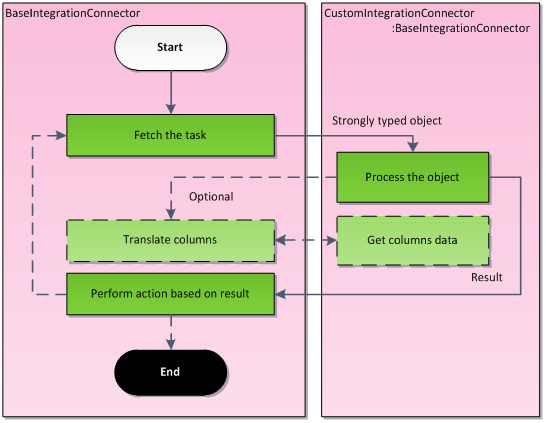
Please note that the BaseIntegrationConnector is already implemented. Your job is to prepare a code based upon this class (in the figure above, it is named CustomIntegrationConnector).
When using synchronous processing, the changed object goes directly to the connector for further processing:

The following diagram illustrates the detailed order of the events:
The major advantage of this attitude is that you can manipulate with the object in the context of Kentico CMS. This means that you can access properties like Parent or Children and the data are fetched from the database just in time. When it comes to documents, you can access properties like Tags, Categories and Attachments. On the other hand, you lose the option of persisting object and document data in the database (for the case when something goes wrong and the connector fails to process the request). Another disadvantage results from the nature of this type of synchronous processing — it slows down the page life cycle. It is recommended to use synchronous processing only when it is necessary for a specific reason.
Processing of synchronous tasks starts immediately after some object or document matching some subscription is changed. Unlike the asynchronous processing where the logging and processing is postponed till the application reaches EndRequest, this type of processing sends the data instantly to the subscribed connectors.