|
|

Defining document index content |

|

|

|

|
|
Defining document index content |
|
|

|
|
|
|
Defining document index content |
|
|
|
|
|
Defining document index content |
|
|
|
|
|
|
||
There are two types of search indexes available for the documents in a website's content tree. Documents type indexes include information from general document fields such as metadata, the text content of certain web parts placed on page (menu item) documents, as well as the selected fields of individual documents types as described in the Settings for particular object types topic. Data from other documents or objects displayed by web parts is not indexed. For example, the content of news documents displayed by a Repeater web part placed on an indexed document will not be added to the index etc.
Documents crawler type indexes directly parse the HTML output generated by documents, which means that all text located on or associated with a document is searchable. This allows document content to be searched more accurately than using a Documents type index. However, building and updating a Documents crawler index may require more time and resources, particularly in the case of large indexes and complex documents. The crawler accesses documents under a specific user account, which may be specified using keys in your project's web.config file. All keys related to smart search indexes may be found in the Smart search settings section of Appendix B - Web.config parameters.
The process used to define which documents on the site should be indexed is the same for both document index types. This is done by specifying allowed and excluded content on the Index tab of the interface displayed when editing an index.
The dialogs for defining new allowed/excluded content can be accessed using the ![]() Add allowed content and
Add allowed content and ![]() Add excluded content links.
Add excluded content links.
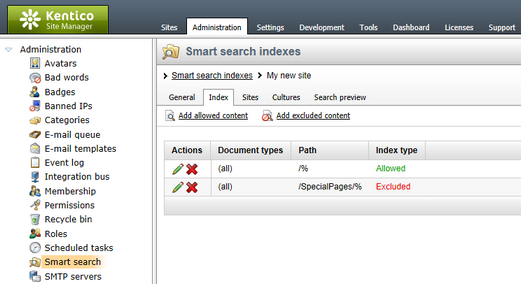
In this dialog, you are defining what part of the website will be indexed. You can specify this by choosing the Path to the indexed documents, Document types of the indexed documents or a combination of both. The following options can be specified:
•Path - path to the documents that should be indexed.
•Document types - document types that should be included in indexing.
The following properties define types of additional content that may be included in Documents search indexes. They are not available for Documents crawler indexes:
•Including ad-hoc forums - if checked, ad-hoc forums placed on documents specified by the properties above (if there are any) will be indexed too.
•Including blog comments - if checked, blog comments placed on blog posts specified by the properties above (if there are any) will be indexed too.
•Including message boards - if checked, message boards placed on documents specified by the properties above will be indexed too.
Documents that have their Exclude this document from search property enabled will not be indexed. This property can be configured by selecting a document from the content tree in CMS Desk and going to Content -> Edit -> Properties -> General.
Examples:
•Path: /%
•Document types: empty
In this case, all documents on the site will be indexed.
•Path: /Partners
•Document types: empty
In this case, only the /Partners page will be indexed, without the pages under it.
•Path: empty
•Document types: CMS.News
In this case, all documents of the CMS.News document type on the whole site will be indexed. Please note that in this case, the empty path field is equal to /%.
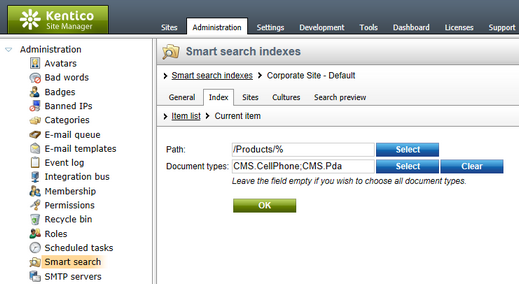
•Path: /Products/%
•Document types: CMS.CellPhone;CMS.Pda
In this case, all documents of the CMS.CellPhone and CMS.Pda document types found under /Products will be indexed.
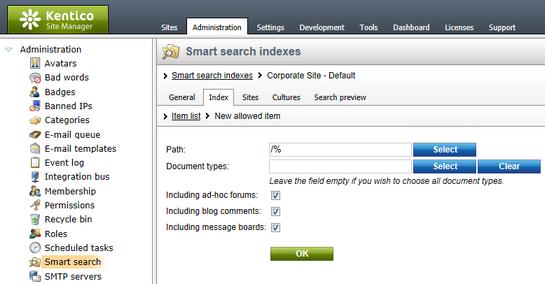
In this dialog, you are defining what part of the website will be excluded from indexing.
Excluded content is removed from the allowed content. So for example if you allow /% and exclude /Special-pages/% at the same time, it means that all pages on the site will be indexed, except for all pages found under the /Special-pages node.
The following options can be specified:
•Path: path to the documents that should be indexed
•Document types: document types that should be included in indexing
Examples:
•Path: /Partners
•Document types: empty
In this case, only the /Partners page will be excluded from indexing, not the pages under it.
•Path: empty
•Document types: CMS.News
In this case, all documents of the CMS.News document type on the whole site will be excluded from indexing. Please note that in this case, the empty path field is equal to /%.
•Path: /Products/%
•Document types: CMS.CellPhone;CMS.Pda
In this case, all documents of the CMS.CellPhone and CMS.Pda document types found under /Products will be excluded from indexing.
By default, the output of documents is converted to plain text (stripped of all HTML tags, JavaScript and whitespace formatting) before it is saved to the index. It is possible to change this behavior if you wish to store the content of any tags in documents crawler indexes. This can be done by implementing custom functionality in a handler for the OnHtmlToPlainText event of the CMS.SiteProvider.SearchHelper class, which is triggered when the HTML output is processed by a crawler.
For example, the customization can be performed by adding a custom class to the ~/App_Code folder (or ~/Old_App_Code if you installed the project as a web application). You can define the content of the class as shown below:
[C#]
using CMS.SettingsProvider; |
The plainText parameter contains the document output already stripped of all tags and converted to plain text, while originalHTML can be used to access the raw page code without any modifications.