|
|

Monitoring traffic from search engines |

|

|

|

|
|
Monitoring traffic from search engines |
|
|

|
|
|
|
Monitoring traffic from search engines |
|
|
|
|
|
Monitoring traffic from search engines |
|
|
|
|
|
|
||
Search engine tracking allows you to monitor the amount of page views received from visitors who found the website using a search engine. Since search engines are the most common type of referring websites, they are tracked separately and with additional details.
The report containing this data can be accessed through the web analytics tree menu in Traffic sources -> Search engines. As shown below, it contains a graph displaying the total amount of page views generated by search engine traffic and a breakdown of the statistics for individual search engines.
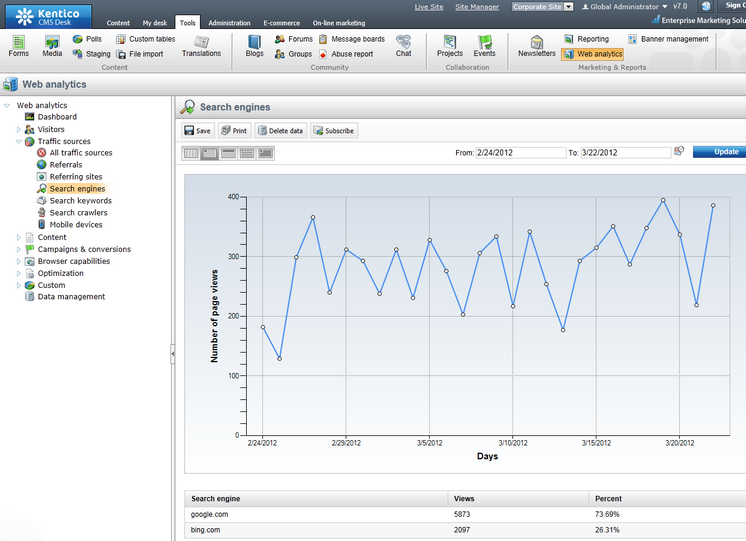
Additionally, it is possible to view the exact keywords that were entered into the search engines using the Search keywords report (also located under the Traffic sources category).
Before they can provide search results that link users to your website, search engines need to index the site using web crawlers (robots). The web analytics module is also capable of tracking the activity of these crawlers on your website's pages, and the results can be reviewed in the Search crawlers report.
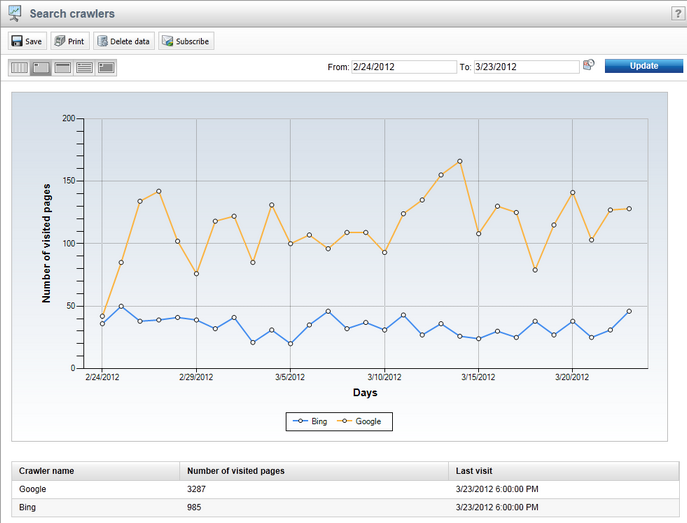
The data provided in this report can be useful when performing Search engine optimization of your website. These statistics can also be checked for specific pages by selecting the corresponding document in the content tree of CMS Desk and viewing its Traffic sources reports on the Analytics -> Reports tab.
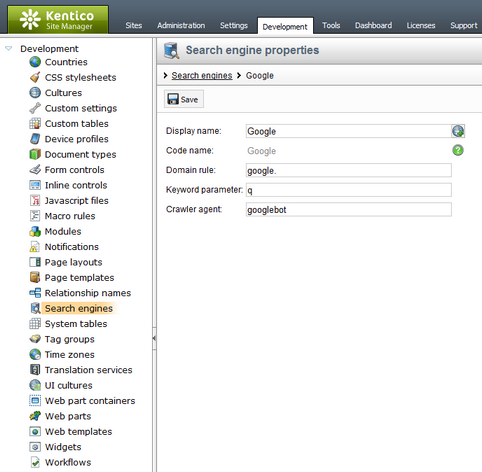
In order to correctly log incoming traffic from search engines, objects representing individual engines must be defined in the system. This can be done in Site Manager -> Development -> Search engines. By default, the list contains some of the most commonly used search engines, but any additional ones that you wish to track must be added manually.
When creating or editing (![]() ) a search engine object, the following properties can be specified:
) a search engine object, the following properties can be specified:
•Display name - sets the name of the search engine used in the administration and web analytics interface.
•Code name - may be used to set a unique identifier for the search engine. You can leave the default (automatic) option to have the system generate an appropriate code name.
•Domain rule - this string is used to identify whether website traffic originates from the given search engine. In order to work correctly, this string must always be present in the engine's URL, for example google. for the Google search engine.
•Keyword parameter - specifies the name of the query string parameter that the given search engine uses to store the keywords entered when a search request is submitted. This is necessary so that the system can log which search keywords visitors used to find the website.
•Crawler agent - sets the user agent that will be used to identify which web crawlers (robots) belong to this search engine. Examples of common crawler agents are Googlebot for Google, or msnbot for Bing. This property is optional and it is recommended to specify the crawler agent only for major search engines, or those that are relevant to your website.
If the site is accessed from an external website, the system parses the URL of the page that generated the request. First, the URL is checked for the presence of a valid Domain rule that matches the value specified for a search engine object. Then the query string of the URL is searched for the parameter defined in the corresponding Keyword parameter property to confirm that the referring link was actually generated by search results, not by a banner or other type of link. This allows the system to accurately track user traffic that is gained from search engine results.
Whenever a page is accessed (indexed) by a web robot with a user agent matching the Crawler agent property of one of the search engines registered in the system, a hit is logged in the Search crawlers web analytics statistic.